
国庆节的一个大清早,我就被微信群吵醒了,说是spark实时程序有问题,数据没出来,让我看看。我看了下邮箱,确实有报警信息。我特么,没办法,起床。
1 主键自增id设置不合理引发的bug
首先,我检查了一下应用管理页面,发现资源没有用完,GC也正常,程序正在嗖嗖的跑呢,那怎么会没有今天的数据呢?
看了下日志,error.log里面并没有今天的日志,warn.log里面有sql语句,都很正常,这到底是怎么回事呢?
算了,手动验证一下吧,从warn.log里面复制了一条sql,放在mysql命令行执行,显示:OK 2 row affected.
查询一下,今天还是没有数据,不是已经显示插入成功么,我特么要疯了。
继续插入,报错:
Duplicate entry '4294967295' for key 'PRIMARY'看一下表结构
show create table `tableName`;
CREATE TABLE `tableName` (
`id` bigint(11) unsigned NOT NULL AUTO_INCREMENT,
`count` bigint(20) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;原来是id取无符号整数,数值达到最大4294967295了。
对于int类型的一些基础知识其实上图已经说的很明白了,在这里想讨论下常用的int(11)代表什么意思,很长时间以来我都以为这代表着限制int的长度为11位,直到有天看到篇文章才明白,11代表的并不是长度,而是字符的显示宽度,在字段类型为int时,无论你显示宽度设置为多少,int类型能存储的最大值和最小值永远都是固定的,这里贴一些原文片段。
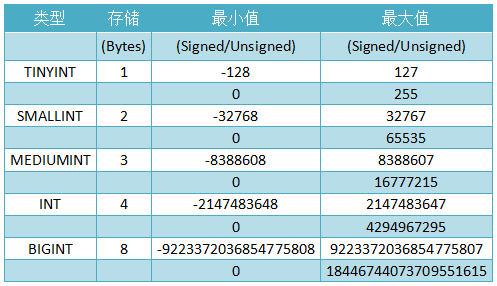
原因:表结构自增id设置不合理,已经达到上限。
解决办法
- 增大id最大值,修改为bigint(20).
alter table `hm3_realtime_flash_view_client` modify id bigint(20) auto_increment;这里需要注意,需要加上auto_increment,否则就不会自增了。
小测试
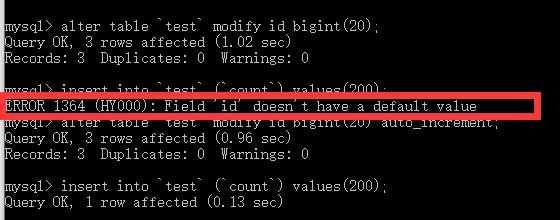
- 设置自增id的起始数值,需要比4294967295大1,即4294967296开始。
alter table `tableName` AUTO_INCREMENT=4294967296;
根本原因
由于有:不存在插入,存在则更新的需求,用了on duplicate key update,自动判断是更新还是新增(MySQL判断记录是否存在的依据是主键或者唯一索引,insert在主键或者唯一索引已经存在的情况下会插入失败,而InsertOrUpdate在主键或者唯一索引已经存在的情况下就变成了根据主键或唯一索引update的操作)。设计表结构时,为了innodb的插入性能,表中使用了一个id自增主键,也有一个几个字段的联合索引,每次update都把AUTO_INCREMENT增大了,导致2个id之间相差不是2,而是很大一个数,造成过早达到主键id的最大值int(11)。
根本有效的解决办法
解决这个问题,有两种方式:
第一种:拆分成两个动作,先更新,更新无效再插入(使用)
1、根据唯一索引来更新表;
update tableName set col = '';2、根据上一步的返回值记为count,如果返回值大于0,说明更新成功不再需要插入数据,如果返回值不大于0则需要进行插入该条数据,伪代码;
if( count == 0){
insert into tableName(col) values();
}第二种:修改innodb_autoinc_lock_mode参数(未使用)
innodb_autoinc_lock_mode中有3种模式,0,1,2,数据库默认是1的情况下,就会发生上面的那种现象,每次使用insert into … on duplicate key update 的时候都会把简单自增id增加,不管是发生了insert还是update
innodb_autoinc_lock_mode参数详解
-
tradition(innodb_autoinc_lock_mode=0)模式:
1、它提供了一个向后兼容的能力
2、在这一模式下,所有的insert语句(“insert like”) 都要在语句开始的时候得到一个表级的auto_inc锁,在语句结束的时候才释放这把锁,注意呀,这里说的是语句级而不是事务级的,一个事务可能包涵有一个或多个语句。
3、它能保证值分配的可预见性,与连续性,可重复性,这个也就保证了insert语句在复制到slave的时候还能生成和master那边一样的值(它保证了基于语句复制的安全)。
4、由于在这种模式下auto_inc锁一直要保持到语句的结束,所以这个就影响到了并发的插入。 -
consecutive(innodb_autoinc_lock_mode=1)模式:
1、这一模式下去simple insert 做了优化,由于simple insert一次性插入值的个数可以立马得到确定,所以mysql可以一次生成几个连续的值,用于这个insert语句;总的来说这个对复制也是安全的(它保证了基于语句复制的安全)
2、这一模式也是mysql的默认模式,这个模式的好处是auto_inc锁不要一直保持到语句的结束,只要语句得到了相应的值后就可以提前释放锁 -
interleaved(innodb_autoinc_lock_mode=2)模式:
1、由于这个模式下已经没有了auto_inc锁,所以这个模式下的性能是最好的;但是它也有一个问题,就是对于同一个语句来说它所得到的auto_incremant值可能不是连续的。
由于用户访问量较大,0模式虽然只有实际的发生insert的时候才增加,但是每次都会在语句执行期间锁表,并发性不太好,所以最终选择使用第一种解决方案,把更新插入语句分开写。
参考:https://blog.csdn.net/eleanoryss/article/details/82997899
2 MySQL为什么需要一个主键
主键
表中每一行都应该有可以唯一标识自己的一列(或一组列)。
一个顾客可以使用顾客编号列,而订单可以使用订单ID,雇员可以使用雇员ID 或 雇员社会保险号。
主键(primary key) 一列(或一组列),其值能够唯一区分表中的每个行。
唯一标识表中每行的这个列(或这组列)称为主键。没有主键,更新或删除表中特定行很困难,因为没有安全的方法保证只设计相关的行。
虽然并不总是都需要主键,但大多数数据库设计人员都应保证他们创建的每个表有一个主键,以便于以后数据操纵和管理
表中的任何列都可以作为主键,只要它满足一下条件:
1、任何两行都不具有相同的主键值
2、每个行都必须具有一个主键值(主键列不允许NULL值)
主键值规范:这里列出的规则是MySQL本身强制实施的。
主键的最好习惯:
除MySQL强制实施的规则外,应该坚持的几个普遍认为的最好习惯为:
- 不更新主键列的值
- 不重用主键列的值
- 不在主键列中使用可能会更改的值(例如,如果使用一个名字作为主键以标识某个供应商,应该供应商合并和更改其名字时,必须更改这个主键)
总之:不应该使用一个具有意义的column(id 本身并不保存表 有意义信息) 作为主键,并且一个表必须要有一个主键,为方便扩展、松耦合,高可用的系统做铺垫。
主键的作用,在于索引。
无特殊需求下Innodb建议使用与业务无关的自增ID作为主键
InnoDB引擎使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
1、如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
2、 如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键。
mysql 在频繁的更新、删除操作,会产生碎片。而含碎片比较大的表,查询效率会降低。此时需对表进行优化,这样才会使查询变得更有效率。
查了一些资料
- https://www.jianshu.com/p/33b7b6e0a396
- https://segmentfault.com/a/1190000012479448
- https://segmentfault.com/q/1010000009807110/a-1020000009810982




文章评论
大点的系统推荐使用字符串来替代数值型,Java中不管有没有负数,不推荐使用unsigned类型,容易因位数不够出bug,字符串空间换时间,也能较好的规避数据库厂商之间的差异等