
1. Hive简介
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2. Hive的安装
安装hive前请确保已经安装好hadoop集群,通常使用mysql作为hive的元数据库,所以需要安装mysql。 我的hadoop集群是用3台虚拟机搭建的,分别是:
master1.hadoop
slave2.hadoop
slave3.hadoophive只需要在hadoop集群的一台节点上面安装即可。安装步骤通常有以下几步: 1 下载hive到本地 我的hadoop版本是2.7.2的,这里选择了hive 2.x版本。国内阿里的镜像速度比较快,可以选择这个版本(我用的版本是hive-2.1.0),地址,下载到本地后并解压。
2 复制hive-site.xml
- 进入
hive-2.1.0\conf目录 - 修改
hive-default.xml.template为hive-site.xml,这个文件是hive的核心配置文件; - 修改
hive-env.sh.template为hive-env.sh; - 修改
hive-log4j2.properties.template为hive-log4j2.properties; - 修改
hive-exec-log4j2.properties.template为hive-exec-log4j2.properties;
3 配置hive-site.xml1). 修改javax.jdo.option.ConnectionURL为你自己的mysql连接,可以在本节点安装mysql,也可以访问其它可访问的mysql;
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master1.hadoop:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>注意:这里在master1.hadoop上面安装了一个mysql,你可以使用你的本地mysql,只需把主机ip信息换一下即可。 2). 修改javax.jdo.option.ConnectionDriverName为mysql的连接驱动
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>3). 修改javax.jdo.option.ConnectionUserName为mysql的用户名root
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>4). 修改javax.jdo.option.ConnectionPassword为mysql的密码:root
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>5). 修改hive.exec.local.scratchdir为指定临时路径
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/hive</value>
<description>Local scratch space for Hive jobs</description>
</property>6). 修改hive.downloaded.resources.dir为指定临时路径
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive/resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>7). 修改hive.querylog.location为指定临时路径
<property>
<name>hive.querylog.location</name>
<value>/tmp/hive</value>
<description>Location of Hive run time structured log file</description>
</property>8). 修改hive.server2.logging.operation.log.location为指定临时路径
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/tmp/hive/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>4 配置hive-env.sh编辑文件vim hive-env.sh,主要配置以下几个值:
HADOOP_HOME=/home/hadoop/hadoop-2.7.2
export HIVE_CONF_DIR=/home/hadoop/hive-2.1.0/conf
export JAVA_HOME=/home/hadoop/jdk1.8.0_73
export HIVE_HOME=/home/hadoop/hive-2.1.05 启动hive
1). 保证有执行权限
chmod 777 /home/hadoop/hive-2.1.0/bin/*
chmod 777 /home/hadoop/hive-2.1.0/lib/*2). 添加环境变量(root用户下) 打开/etc/profile,添加如下内容
...
其它环境变量,省略...
...
export HIVE_HOME=/home/hadoop/hive-2.1.0
export PATH=$HIVE_HOME/bin:$PATH3). 创建hdfs文件夹
- 启动
hdfs; -
在
hdfs系统中,创建/tmp和/user/hive/warehouse两个文件夹 ```bash
hdfs dfs -mkdir /tmp
hdfs dfs -mkdir -p /user/hive/warehouse递归创建hdfs目录用-p参数。 4). 初始化hive运行命令:schematool -dbType mysql -initSchema
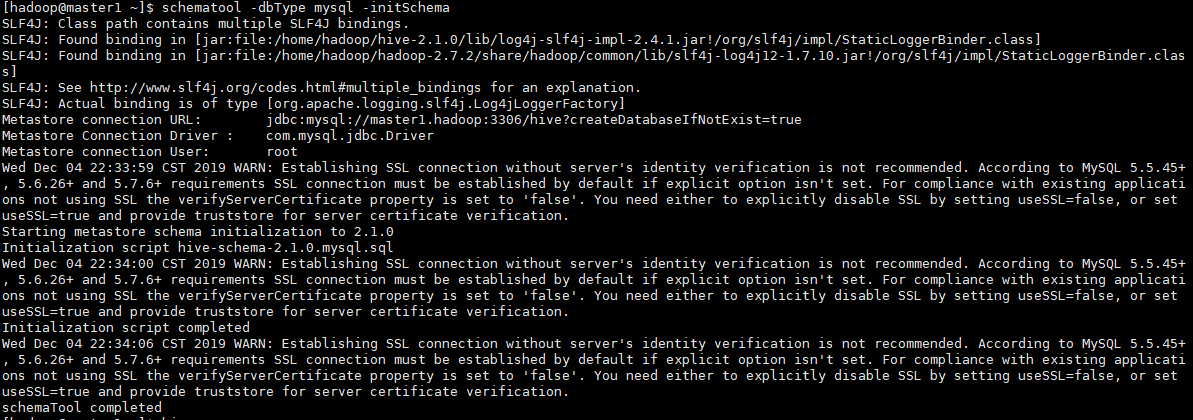
查看mysql,发现hive库和表都已建好
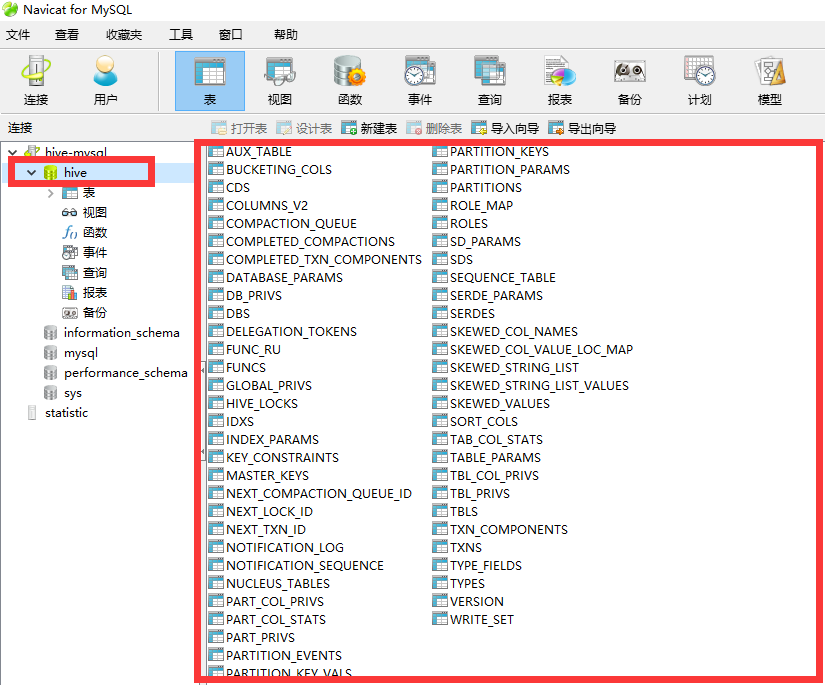
5). 如果前面步骤配置的没有问题,命令行输入hive命令即可。
hive> show databases;
OK
default
Time taken: 2.184 seconds, Fetched: 1 row(s)



文章评论