
Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
- 第10讲:Flink Side OutPut 分流
- 第11讲:Flink CEP 复杂事件处理
- 第12讲:Flink 常用的 Source 和 Connector
- 第13讲:如何实现生产环境中的 Flink 高可用配置
- 第14讲:Flink Exactly-once 实现原理解析
- 第15讲:如何排查生产环境中的反压问题
- 第16讲:如何处理Flink生产环境中的数据倾斜问题
- 第17讲:生产环境中的并行度和资源设置
关注公众号:
大数据技术派,回复资料,领取1024G资料。
这一课时我们主要讲解生产环境中 Flink 任务经常会遇到的一个问题,即如何处理好反压问题将直接关系到任务的资源使用和稳定运行。
反压问题是流式计算系统中经常碰到的一个问题,如果你的任务出现反压节点,那么就意味着任务数据的消费速度小于数据的生产速度,需要对生产数据的速度进行控制。通常情况下,反压经常出现在促销、热门活动等场景,它们有一个共同的特点:短时间内流量陡增造成数据的堆积或者消费速度变慢。
不同框架的反压对比
目前主流的大数据实时处理系统都对反压问题进行了专门的处理,希望框架自身能检测到被阻塞的算子,然后降低数据生产者的发送速率。我们所熟悉的 Storm、Spark Streaming、Flink 的实现稍微有所不同。
Storm
Storm 从 1.0 版本以后引入了全新的反压机制,Storm 会主动监控工作节点。当工作节点接收数据超过一定的水位值时,那么反压信息会被发送到 ZooKeeper 上,然后 ZooKeeper 通知所有的工作节点进入反压状态,最后数据的生产源头会降低数据的发送速度。
Spark Streaming
Spark Streaming 在原有的架构基础上专门设计了一个 RateController 组件,该组件利用经典的 PID 算法。向系统反馈当前系统处理数据的几个重要属性:消息数量、调度时间、处理时间、调度时间等,然后根据这些参数计算出一个速率,该速率则是当前系统处理数据的最大能力,Spark Streaming 会根据计算结果对生产者进行限速。
Flink
Flink 的反压设计利用了网络传输和动态限流。在 Flink 的设计哲学中,纯流式计算给 Flink 进行反压设计提供了天然的优势。
我们在以前的课程中讲解过,Flink 任务的组成由基本的“流”和“算子”构成,那么“流”中的数据在“算子”间进行计算和转换时,会被放入分布式的阻塞队列中。当消费者的阻塞队列满时,则会降低生产者的数据生产速度。

如上图所示,我们看一下 Flink 进行逐级反压的过程。当 Task C 的数据处理速度发生异常时,Receive Buffer 会呈现出队列满的情况,Task B 的 Send Buffer 会感知到这一点,然后把数据发送速度降低。以此类推,整个反压会一直从下向上传递到 Source 端;反之,当下游的 Task 处理能力有提升后,会在此反馈到 Source Task,数据的发送和读取速率都会升高,提高了整个任务的处理能力。
反压的定位
当你的任务出现反压时,如果你的上游是类似 Kafka 的消息系统,很明显的表现就是消费速度变慢,Kafka 消息出现堆积。
如果你的业务对数据延迟要求并不高,那么反压其实并没有很大的影响。但是对于规模很大的集群中的大作业,反压会造成严重的“并发症”。首先任务状态会变得很大,因为数据大规模堆积在系统中,这些暂时不被处理的数据同样会被放到“状态”中。另外,Flink 会因为数据堆积和处理速度变慢导致 checkpoint 超时,而 checkpoint 是 Flink 保证数据一致性的关键所在,最终会导致数据的不一致发生。
那么我们应该如何发现任务是否出现反压了呢?
Flink Web UI
Flink 的后台页面是我们发现反压问题的第一选择。Flink 的后台页面可以直观、清晰地看到当前作业的运行状态。
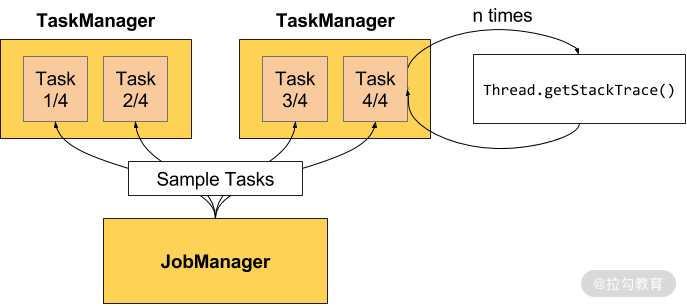
如上图所示,是 Flink 官网给出的计算反压状态的案例。需要注意的是,只有用户在访问点击某一个作业时,才会触发反压状态的计算。在默认的设置下,Flink 的 TaskManager 会每隔 50 ms 触发一次反压状态监测,共监测 100 次,并将计算结果反馈给 JobManager,最后由 JobManager 进行计算反压的比例,然后进行展示。
这个比例展示逻辑如下:
OK: 0 <= Ratio <= 0.10,正常;
LOW: 0.10 < Ratio <= 0.5,一般;
HIGH: 0.5 < Ratio <= 1,严重。
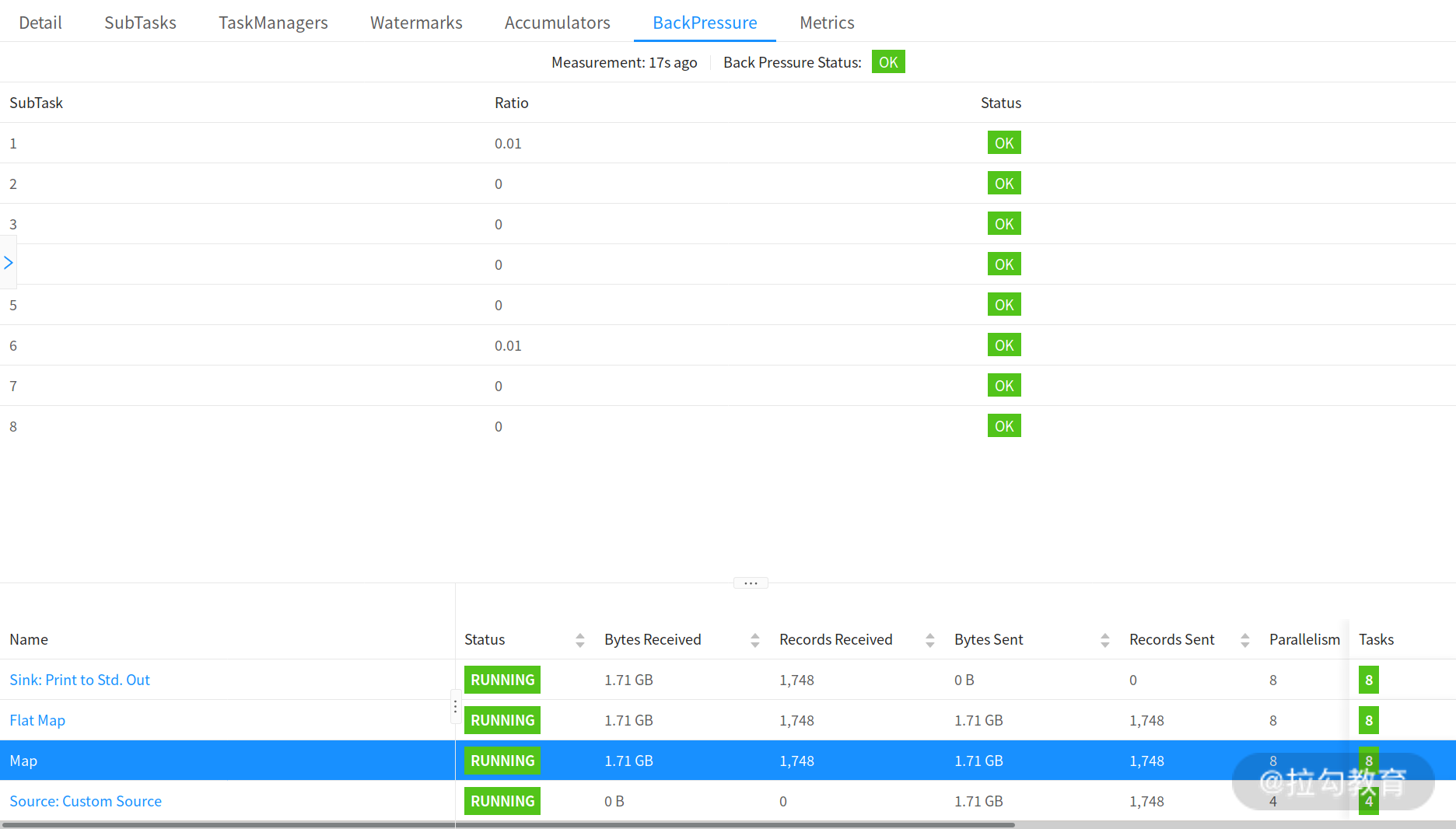
官网同样给出了不同反压状态下,Flink Web UI 中任务运行的状态,如下图所示:
Flink Metrics
如果你想对 Flink 做更为详细的监控的话,Flink 本身提供了大量的 REST API 来获取任务的各种状态。Flink 提供的所有系统监控指标你都点击这里找到。
随着版本的持续变更,截止 1.10.0 版本,Flink 提供的监控指标中与反压最为密切的如下表所示:
| 指标名称 | 用途 |
|---|---|
| outPoolUsage | 发送端缓冲池的使用率 |
| inPoolUsage | 接收端缓冲池的使用率 |
| floatingBuffersUsage | 处理节点缓冲池的使用率 |
| exclusiveBuffersUsage | 数据输入方缓冲池的使用率 |
outPoolUsage
这个指标代表的是当前 Task 的数据发送速率,当一个 Task 的 outPoolUsage 很高,则代表着数据发送速度很快。但是当一个 Task 的 outPoolUsage 很低,那么就需要特别注意,有可能是下游的处理速度很低导致的,也有可能当前节点就是反压节点,导致数据处理速度很慢。
inPoolUsage
inPoolUsage 表示当前 Task 的数据接收速率,通常会和 outPoolUsage 配合使用;如果一个节点的 inPoolUsage 很高而 outPoolUsage 很低,则这个节点很有可能就是反压节点。
floatingBuffersUsage 和 exclusiveBuffersUsage
floatingBuffersUsage 表示处理节点缓冲池的使用率;exclusiveBuffersUsage 表示数据输入通道缓冲池的使用率。
反压问题处理
我们已经知道反压产生的原因和监控的方法,当线上任务出现反压时,需要如何处理呢?
主要通过以下几个方面进行定位和处理:
-
数据倾斜
-
GC
-
代码本身
数据倾斜
数据倾斜问题是我们生产环境中出现频率最多的影响任务运行的因素,可以在 Flink 的后台管理页面看到每个 Task 处理数据的大小。当数据倾斜出现时,通常是简单地使用类似 KeyBy 等分组聚合函数导致的,需要用户将热点 Key 进行预处理,降低或者消除热点 Key 的影响。
GC
垃圾回收问题也是造成反压的因素之一。不合理的设置 TaskManager 的垃圾回收参数会导致严重的 GC 问题,我们可以通过 -XX:+PrintGCDetails 参数查看 GC 的日志。
代码本身
开发者错误地使用 Flink 算子,没有深入了解算子的实现机制导致性能问题。我们可以通过查看运行机器节点的 CPU 和内存情况定位问题。
总结
这一课时我们主要讨论了反压问题,涉及不同框架对反压问题的处理方式、Flink 任务反压的定位和如何处理。我们可以通过多种方式监控 Flink 任务的运行状态来定位反压问题,避免在生产环境中出现严重事故。




文章评论