
概论
- LinkedHashMap 通过特有底层双向链表的支持,使得LinkedHashMap可以保存元素之间的顺序,例如插入顺序或者访问顺序,而HashMap因为没有双向链表的支持,所以就不能保持这种顺序,所以它的访问就是随机的了
- 和HashMap一样,还是通过数组存储元素的
- 这里的顺序指的是遍历的顺序,定义了头结点head,当我们调用迭代器进行遍历时,通过head开始遍历,通过after属性可以不断找到下一个,直到tail尾结点,从而实现顺序性。在同一个hash(其实更准确的说是同一个下标,数组index ,在上图中表现了同一列)链表内部next和HashMap.Node.next 的效果是一样的。不同点在于before和after可以连接不同hash之间的链表,也就是说双向链表是可以跨任何index 连接的,也就是说将LinkedHashMap里面的所有元素按照特定的顺序连接起来的
LinkedHashMap 的最终形态
- 图中的黑色箭头表示next指针,这跟HashMap是一样的;
- 图中的红色箭头表示before和after指针,分别指向这个节点的前面和后面一个节点,这就可以实现有序访问;
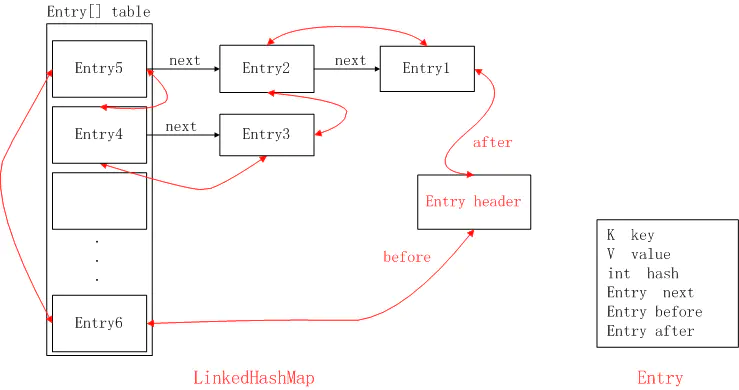
初识LinkedHashMap
我们想在页面展示一周内的消费变化情况,用echarts面积图进行展示。如下:
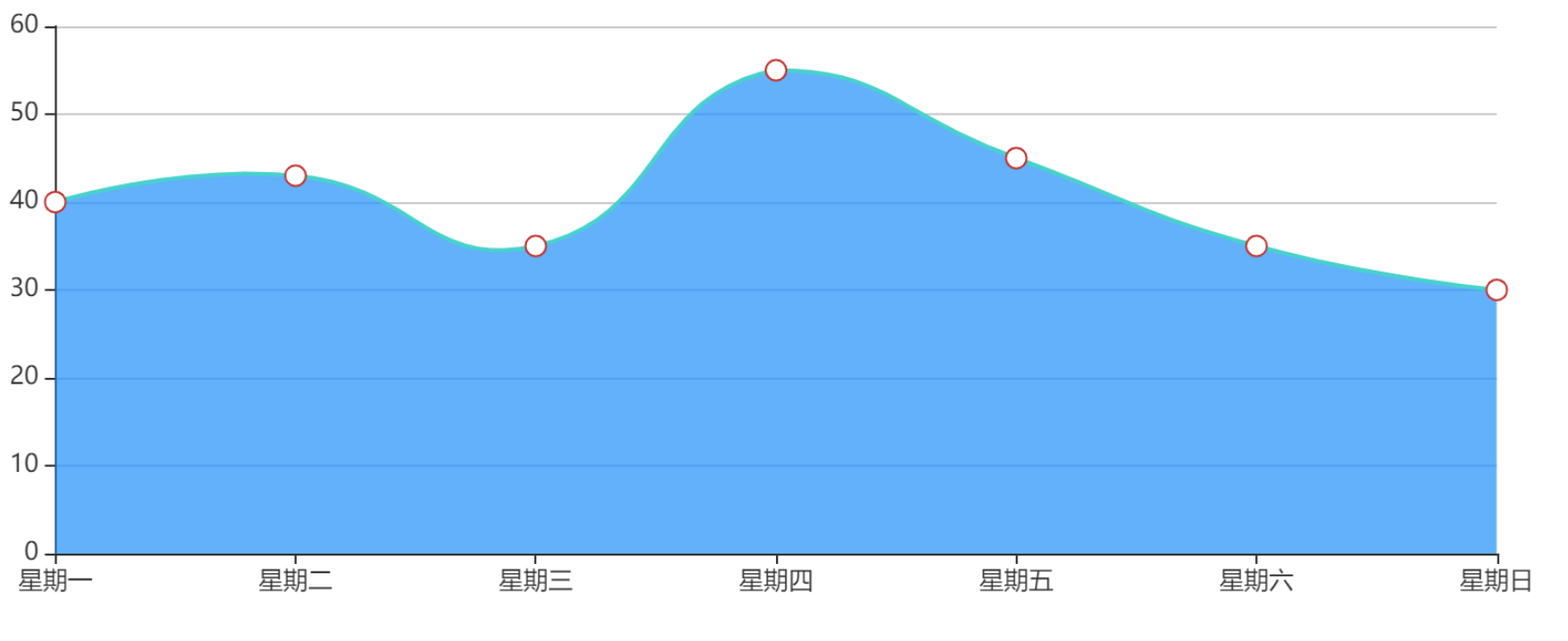
我们在后台将数据构造完成
HashMap<String, Integer> map = new HashMap<>();
map.put("星期一", 40);
map.put("星期二", 43);
map.put("星期三", 35);
map.put("星期四", 55);
map.put("星期五", 45);
map.put("星期六", 35);
map.put("星期日", 30);
for (Map.Entry<String, Integer> entry : map.entrySet()){
System.out.println("key: " + entry.getKey() + ", value: " + entry.getValue());
}
/**
* 结果如下:
* key: 星期二, value: 40
* key: 星期六, value: 35
* key: 星期三, value: 50
* key: 星期四, value: 55
* key: 星期五, value: 45
* key: 星期日, value: 65
* key: 星期一, value: 30
*/然而页面上一展示,发现并非如此,我们打印出来看,发现顺序并非我们所想,先put进去的先get出来
那么如何保证预期展示结果如我们所想呢,这个时候就需要用到LinkedHashMap实体,首先我们把上述代码用LinkedHashMap进行重构
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("星期一", 40);
map.put("星期二", 43);
map.put("星期三", 35);
map.put("星期四", 55);
map.put("星期五", 45);
map.put("星期六", 35);
map.put("星期日", 30);
for (Map.Entry<String, Integer> entry : map.entrySet()){
System.out.println("key: " + entry.getKey() + ", value: " + entry.getValue());
}这个时候,结果正如我们所预期
key: 星期一, value: 40
key: 星期二, value: 43
key: 星期三, value: 35
key: 星期四, value: 55
key: 星期五, value: 45
key: 星期六, value: 35
key: 星期日, value: 30LinkedHashMap 的继承关系
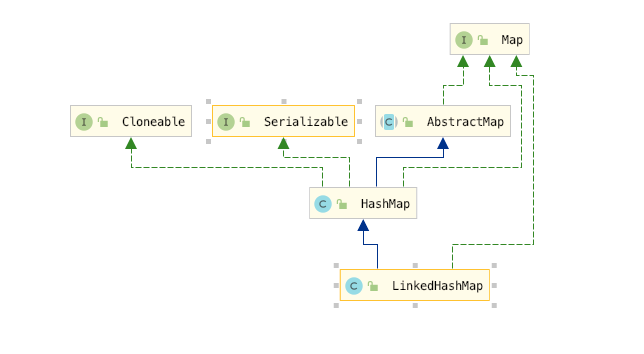
继承关系图
LinkedHashMap继承了HashMap类,是HashMap的子类,LinkedHashMap的大多数方法的实现直接使用了父类HashMap的方法,LinkedHashMap可以说是HashMap和LinkedList的集合体,既使用了HashMap的数据结构,又借用了LinkedList双向链表的结构保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
构造方法
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}我们发现除了多了一个变量accessOrder之外,并无不同,此变量到底起了什么作用?
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;通过注释发现该变量为true时access-order,即按访问顺序遍历,如果为false,则表示按插入顺序遍历。默认为false
LinkedHashMap 的关键内部构成
Entry
这个元素实际上是继承自HashMap.Node 静态内部类 ,我们知道HashMap.Node 实际上是一个单链表,因为它只有next 节点,但是这里LinkedHashMap.Entry保留了HashMap的数据结构,同时有before, after 两个节点,一个前驱节点一个后继节点,从而实现了双向链表
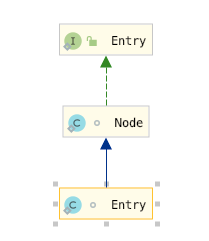
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}accessOrder
通过注释发现该变量为true时access-order,即按访问顺序遍历,此时你任何一次的操作,包括put、get操作,都会改变map中已有的存储顺序
如果为false,则表示按插入顺序遍历。默认为false 也就是按照插入顺序
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;head tail
为了方便操作,加上有是双向链表所有这里定义了两个特殊的节点,头结点和尾部节点
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;newNode方法
LinkedHashMap重写了newNode()方法,通过此方法保证了插入的顺序性,在此之前我们先看一下HashMap 的newNode()方法
// Create a regular (non-tree) node
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}然后我们再看一下LinkedHashMap的newNode()方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}这里调用了一个方法 linkNodeLast(),我们看一下这个方法,但是这和方法不止完成了串联后置,也完成了串联前置,所以插入的顺序性是通过这个方法保证的。
// link at the end of list 将链表的尾节点和当前节点串起来
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
// 将tail 的原始值记做last,因为下面要对 tail 赋值
LinkedHashMap.Entry<K,V> last = tail;
//将新创建的节点p作为尾结点tail
tail = p;
// 如果last是null 也就是当前节点是第一个节点,否则last 不可能是null
if (last == null)
// 因为是第一个节点,所以该节点也是head,所以该节点既是head 又是tail
head = p;
else {
// 此时p是tail节点,那么原来的tail节点将成为 p节点前置节点,p 节点也就是新的节点将成为原来节点的后置节点
p.before = last;
last.after = p;
}
}afterNodeAccess 方法
这里将HashMap 中的实现也帖了出来
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }关于afterNodeAccess()方法,在HashMap中没给具体实现,而在LinkedHashMap重写了,目的是保证操作过的Node节点永远在最后,从而保证读取的顺序性,在调用put方法和get方法时都会用到
// move node to last 将节点移动到最后(其实从这个注释我们就可以知道,这个方法是干什么的了)
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
// accessOrder 确定是按照访问顺序的,如果当前节点不是最后节点,因为是的话就不用移了
if (accessOrder && (last = tail) != e) {
//p:当前节点 b:当前节点的前一个节点 a:当前节点的后一个节点;
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//将p.after设置为null,断开了与后一个节点的关系,但还未确定其位置
p.after = null;
// 如果 p 的前置是null 也就是b 是null 那么此时 就是第一个节点也就是head ,因为p 要后移,那么此时p 的后置应该是head 了
if (b == null)
head = a;
// 如果不是的话,那么p 的后置也就是a 应该代替p 的位置,成为b 的后置 b->p->a => b->a
else
b.after = a;
// 到这里p 已经成为一个游离的节点了,接下来我们只要找到一个位置将p 安置即可,目前的情况是 b->a ,如果a!=null 的话,也让a 指向 b => 也就是 a b 互指 b<->a
if (a != null)
a.before = b;
// 如果a==null 的话,也就是是b 将成为尾部节点,此时第二次完成last 的赋值,此时last 指向b(这里有个问题是e不是tail 此时 a 就不可能是null)
else
last = b;
// 这里就相当于已经找到了尾节点,( 因为上面a!=null,此时last=tail也不是null,所以只会走else )
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
// 完成新的tail 确定,也就是p 节点,这下就知道上面为什么先让 p.after = null 了吧
tail = p;
++modCount;
}
}前面说到的newNode()方法中调用的 linkNodeLast(Entry e)方法和现在的afterNodeAccess(Node e)都是将传入的Node节点放到最后,那么它们的使用场景如何呢?
在上一节讲HashMap的put流程,如果在对应的hash位置上还没有元素,那么直接new Node()放到数组table中,这个时候对应到LinkedHashMap中,调用了newNode()方法,就会用到linkNodeLast(),将新node放到最后,
如果对应的hash位置上有元素,进行元素值的覆盖时,就会调用afterNodeAccess(),将原本可能不是最后的node节点移动到了最后,下面给出了删减之后的代码逻辑
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
if ((p = tab[i = (n - 1) & hash]) == null)
// 调用linkNodeLast方法将新元素放到最后
tab[i] = newNode(hash, key, value, null);
else {
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 将存在的节点放到最后(因为存在所以是Access,也就是访问存在的元素)
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
// 这里就是插入到了树的叶子节点或者是链表的末尾,也就是说本来就在末尾就不用操作了
afterNodeInsertion(evict);
return null;
}下面给出一个例子
@Test
public void test1() {
// 这里是按照访问顺序排序的
HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
// 每次调用 put() 函数,往 LinkedHashMap 中添加数据的时候,都会将数据添加到链表的尾部
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
// 再次将键值为 3 的数据放入到 LinkedHashMap 的时候,会先查找这个键值是否已经有了,然后,再将已经存在的 (3,11) 删除,并且将新的 (3,26) 放到链表的尾部。
m.put(3, 26);
// 当代码访问到 key 为 5 的数据的时候,我们将被访问到的数据移动到链表的尾部。
m.get(5);
// 那么此时的结果应该是 1 2 3 5 因为 3 和 5 一次被移动到了最后面去
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
}运行结果如下
1
2
3
5afterNodeInsertion 方法
关于afterNodeAccess()方法,在HashMap中依然没给具体实现,可以参考afterNodeAccess 中贴出的源代码
LinkedHashMap中还重写了afterNodeInsertion(boolean evict)方法,它的目的是移除链表中最老的节点对象,也就是当前在头部的节点对象,但实际上在JDK8中不会执行,因为removeEldestEntry方法始终返回false
void afterNodeInsertion(boolean evict) {
// possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}removeEldestEntry 方法的源代码如下
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}afterNodeInsertion 方法的意义是什么呢
因为removeEldestEntry 固定返回false , 那这个方法的意义是什么呢 ?·
afterNodeInsertion方法的evict参数如果为false,表示哈希表处于创建模式。只有在使用Map集合作为构造器参数创建LinkedHashMap或HashMap时才会为false,使用其他构造器创建的LinkedHashMap,之后再调用put方法,该参数均为true。
下面给出了单独put 的情况
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) 这里是使用Map集合作为构造器参数创建的时的情况
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
/**
* Implements Map.putAll and Map constructor.
*
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}哈哈,其实到这里还是没有说这个方法的意义是什么,这里我们回过头来想一下,看一下HashMap 中有类似的操作吗,其实有的,就是这三个方法
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }很明显这三个方法,都在LinkedHashMap 中被重写了,所以下面的方法是因为是有返回值的,所以它不在是空方法体了,而是一个直接返回false 的方法体了
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}所以这里的意义就是让你去实现,为什么这么做呢?LinkedHashMap 就是用在记录顺序的场景下,一个典型应用就是LRU,也就是主要用在缓存上面,因为此时的设计虽然保留了LRU的基本特性,但是整个链表的大小是没有限制的
大小没有限制的缓存,哈哈 你懂了,后面肯定就是无限的GC了,因为这里都是强引用
实现一个大小确定的LRU(LinkedHashMap)
如果一个链表只能维持10个元素,那么当插入了第11个元素时,以如下方式重写removeEldestEntry的话,那么将会删除最老的一个元素
public class BuerLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private int maxCacheSiz;
public BuerLinkedHashMap(int maxCacheSize) {
super();
this.maxCacheSiz = maxCacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
if (size() > maxCacheSiz) {
System.out.println("即将执行删除");
return true;
} else {
return false;
}
}
public static void main(String[] args) {
BuerLinkedHashMap<Integer, Integer> buerLinkedHashMap = new BuerLinkedHashMap(10);
LinkedHashMap<Integer, Integer> linkedHashMap = new LinkedHashMap(10);
for (int i = 0; i < 11; i++) {
buerLinkedHashMap.put(i, i);
linkedHashMap.put(i, i);
}
System.out.println("不二map的大小:"+buerLinkedHashMap.size());
System.out.println("默认map的大小:"+linkedHashMap.size());
}
}程序的运行结果如下
即将执行删除
不二map的大小:10
默认map的大小:11afterNodeRemoval 方法
这个方法和上面的方法一样,在HashMap 中都是没有实现的,但是在LinkedHashMap的实现如下,其实这个方法是在删除节点后调用的,可以思考一下为甚么
void afterNodeRemoval(Node<K,V> e) { // unlink
// 将要删除的节点标记为p, b 是p 的前置,a 是p 的后置
LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 切点p 的前后连接
p.before = p.after = null;
// p 的前置是null 的话,p 是要被删除的,那么p 的后置将成为head
if (b == null)
head = a;
// p 的前置b 不是null 的话,b的前置p指向b的后置a即可, 也就是 b->p->a => b->a
else
b.after = a;
// a 是null 的话,p 则是原来的tail,那么新的tail 就是 b
if (a == null)
tail = b;
// 如果a 不是null 则是一个普通的节点,也就是说删除的不是tail 则让a 也指向b
else
a.before = b;
}因为LinkedHashMap 的双向链表连接了LinkedHashMap中的所有元素,HashMap中的删除方法可以使没有考虑这些的,它只考虑了如何存红黑树、链表中删除节点,所以它是不维护双向链表的,所以这里才有了这个方法的实现
debug 源码 插入元素的过程
有了HashMap 那一节和前面的铺垫,接下来我们看一下完整的插入过程,下面将和HashMap 不一样的地方标注出来
其他细节请参考上一篇HashMap,因为 DRY(don't repeat yourself)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// 首先newNode方法是重写了的,在插入元素的同时将元素放到了链表的尾部,具体可以参考上面对这个方法的解析
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 这里说明这个key 已经存在,就相当于与是对这个key 的一次访问,所以访问结束之后调用了 afterNodeAccess(e),其实这里还有一点要说明,即使存在的key 是在链表的尾部或者是在树的叶子节点
// 也算是访问,所以这里并没有要求位置,只要求存在,所以afterNodeAccess 中判断了e 是不是 tail
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
// 这个方法和 afterNodeAccess(e) linkNodeLast(p) 都不一样,因为它没有传入元素,下面单独对着一点进行解释一下
afterNodeInsertion(evict);
return null;
}获取元素的过程
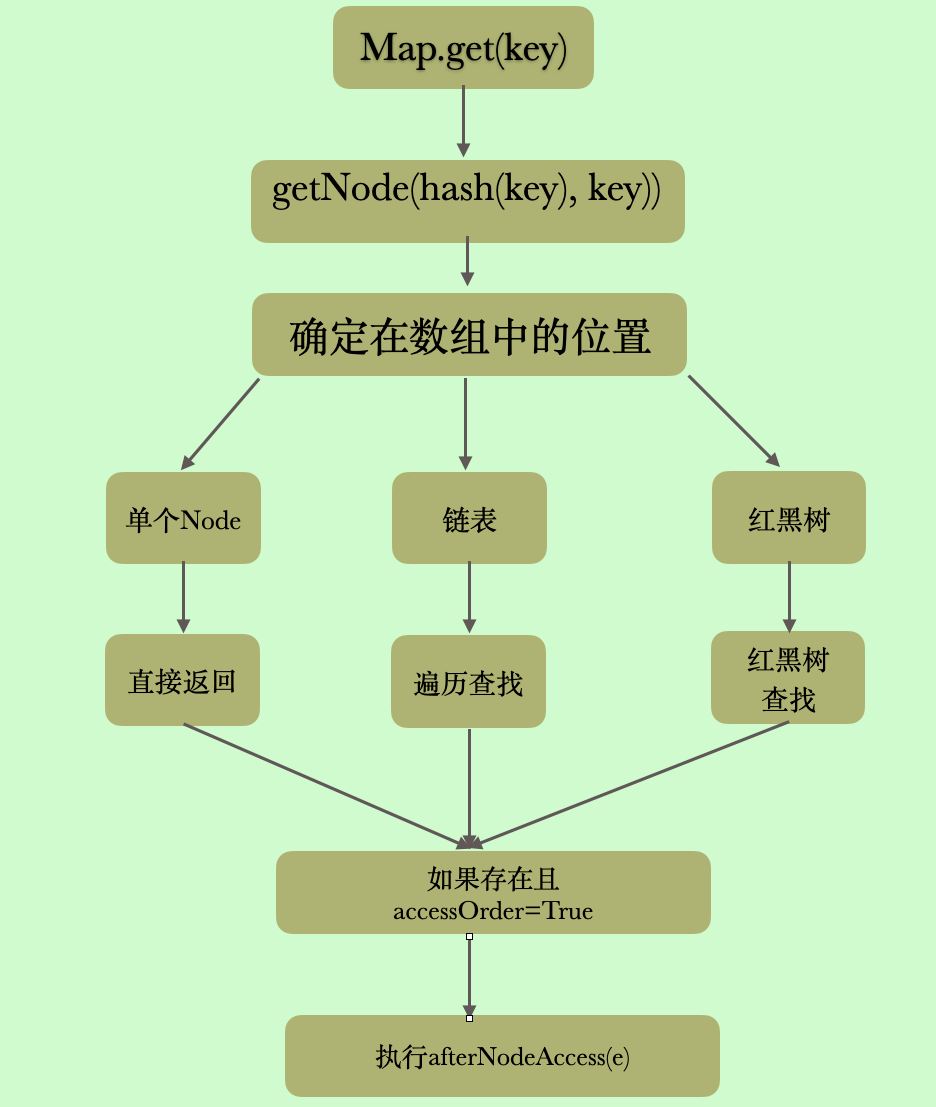
首先 LinkedHashMap 重写了get 方法,getNode 方法依然使用的实HashMap 的,当元素存在的时候,判断是否要根据accessOrder 将元素移动到双向链表的尾部
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
删除元素的过程
Hashmap 一节,我们也没有讲remove 方法,所以这里我们来看一下,细节的一些东西都写在注释里了,首先remove 方法是有返回值的,存在则返回key 对应的value 不存在则返回null
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
// 实际执行删除的方法
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// 数组不为空且有元素,并且tab[index = (n - 1) & hash]!=null 也就是这个桶上得有元素,不是空桶 否则返回null
if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
// node 要删除的节点
Node<K,V> node = null, e; K k; V v;
//p 就是当前节点,也就是和我们要删除的key 在同一个桶上的第一个节点,判断p 是不是要删除的节点 是则标记为node
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
node = p;
// 不是的话,开始遍历,可能是链表可能是树,前提是当前节点的next 节点那不为空,如果为空的话,就不用遍历了
//因为当前节点不是要删除的节点,并且当前节点么有next,那就是不存在了
else if ((e = p.next) != null) {
// 判断是不是树
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
// 不是树的话,那就一定是链表了
do {
// 这个判断方式和上面的判断方式是一样的,找到了要删除的节点就跳出循环
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {
node = e;
break;
}
// p 是 e 的前一个节点,当node 是要删除的节点的时候,p 就是待删除节点的前一个节点
p = e;
} while ((e = e.next) != null);
}
}
// 判断有没有找到要删除的节点,并且这里有其他的条件,因为上面判断是不是要删除的节点仅仅判断了key 是不是同一个key
if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {
// 树删除
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
// 此时只有一个节点,也就是也就是一开始的第一个if 处的判断条件为true,就是说要删除节点就是链表的第一个节点
else if (node == p)
tab[index] = node.next;
// 链表删除,此时p 是node 的前一个节点
else
p.next = node.next;
// 标记修改
++modCount;
// 修改size 大小
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}matchValue 判断删除的时候,是否要求节点的值是相同的,True 则表示找到key相同的节点之后,还需要判断值是相等的才可以使删除。下面就是判断条件,可以自己分析一下
(!matchValue || (v = node.value) == value || (value != null && value.equals(v)))LinkedHashMap重写了其中的afterNodeRemoval(Node e),该方法在HashMap中没有具体实现,通过此方法在删除节点的时候调整了双链表的结构。
总结
LinkedHashMap 的有序性
LinkedHashMap 指的是遍历的时候的有序性,而有序性是通过双向链表实现的,真实的存储之间是没有顺序的,和Hashmap 一样
如何实现一个固定大小的LinkedHashMap
继承LinkedHashMap实现removeEldestEntry 方法,当插入成功后,判断是否要删除最老节点
四个维护双向链表的方法
afterNodeAccess(Node<K,V> p)
访问元素之后维护
afterNodeInsertion(boolean evict)
插入元素之后维护
afterNodeRemoval(Node<K,V> p)
删除元素之后维护
linkNodeLast
也是插入元素之后维护,但是只用于桶上的第一个节点,后面的节点都是用afterNodeAccess或者afterNodeInsertion
你觉得LinkedHashMap 还有什么可以改进的地方吗,欢迎讨论
和上一节一样这里我依然给出这个思考题,虽然我们的说法可能不对,可能我们永远也站不到源代码作者当年的高度,但是我们依然积极思考,大胆讨论
虽然java 源代码的山很高,如果你想跨越,至少你得有登山的勇气,这里我给出自己的一点点愚见,希望各位不吝指教
afterNodeAccess() 方里面有几处判断个人觉得是不需要的,具体可以看afterNodeAccess方法里我写的注释,欢迎大佬讨论,谢谢!





文章评论