
Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
- 第10讲:Flink Side OutPut 分流
- 第11讲:Flink CEP 复杂事件处理
- 第12讲:Flink 常用的 Source 和 Connector
- 第13讲:如何实现生产环境中的 Flink 高可用配置
- 第14讲:Flink Exactly-once 实现原理解析
- 第15讲:如何排查生产环境中的反压问题
- 第16讲:如何处理Flink生产环境中的数据倾斜问题
- 第17讲:生产环境中的并行度和资源设置
我们在第 06 课时“Flink 集群安装部署和 HA 配置”中讲解了 Flink 的几种常见部署模式,并且简单地介绍了 HA 配置。
概述
事实上,集群的高可用(High Availablility,以下简称 HA)配置是大数据领域经典的一个问题。
通常 HA 用来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性。
我们在第 03 课时“Flink 的编程模型与其他框架比较”中也提到过 Flink 集群中的角色,其中 JobManager 扮演的是集群管理者的角色,负责调度任务、协调 Checkpoints、协调故障恢复、收集 Job 的状态信息,并管理 Flink 集群中的从节点 TaskManager。
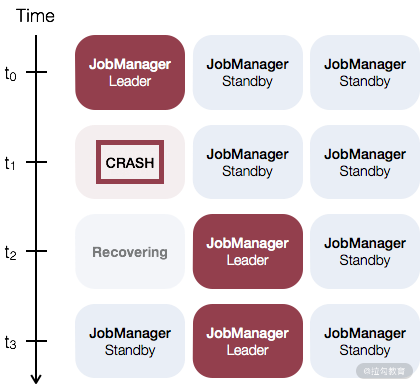
在默认的情况下,我们的每个集群都只有一个 JobManager 实例,假如这个 JobManager 崩溃了,那么将会导致我们的作业运行失败,并且无法提交新的任务。
因此,在生产环境中我们的集群应该如何配置以达到高可用的目的呢?针对不同模式进行部署的集群,我们需要不同的配置。
源码分析
Flink 中的 JobManager、WebServer 等组件都需要高可用保障,并且 Flink 还需要进行 Checkpoint 元数据的持久化操作。与 Flink HA 相关的类图如下图所示,我们跟随源码简单看一下 Flink HA 的实现。

HighAvailabilityMode 类中定义了三种高可用性模式枚举,如下图所示:
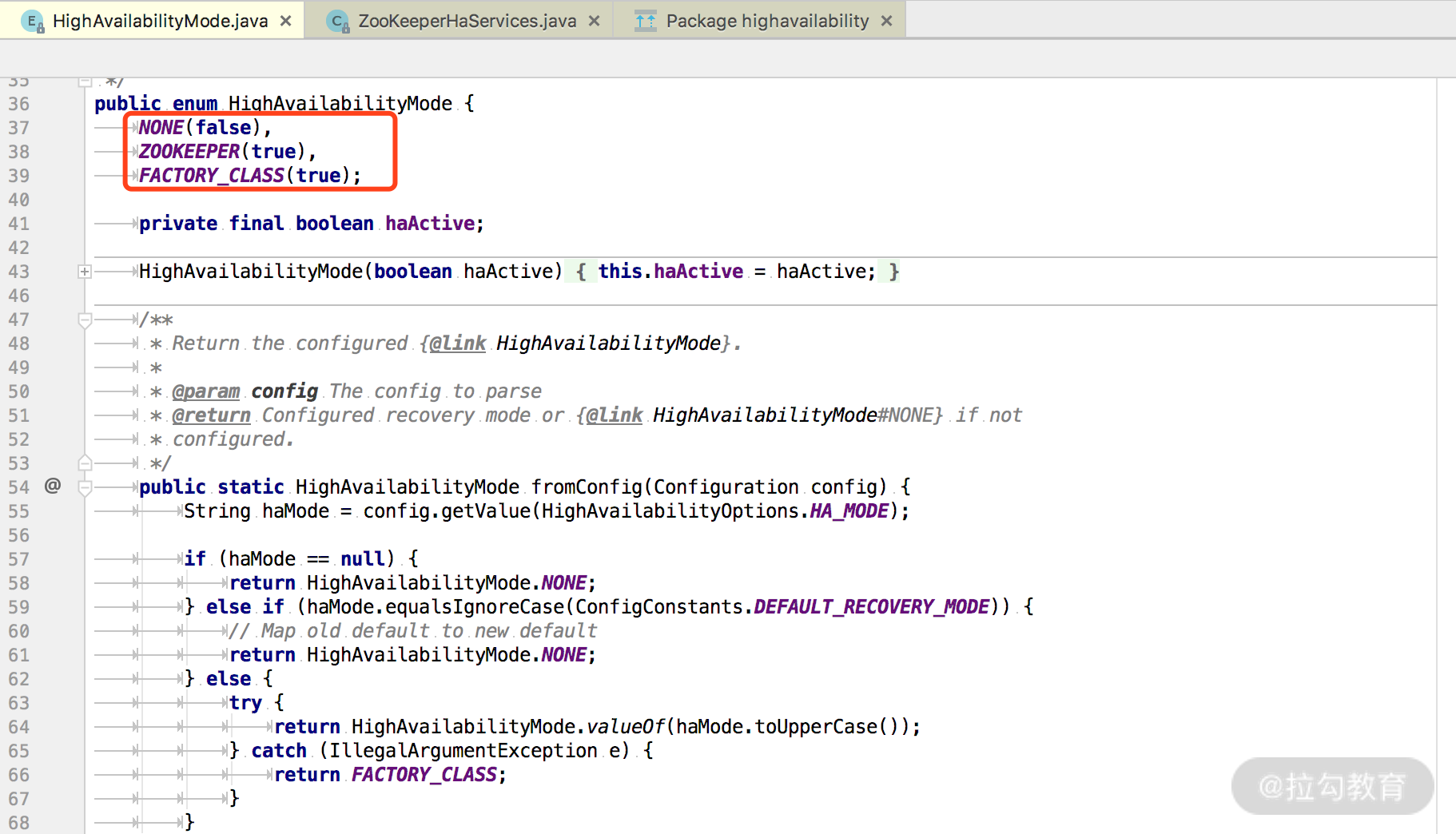
NONE:非 HA 模式
ZOOKEEPER:基于 ZK 实现 HA
FACTORY_CLASS:自定义 HA 工厂类,该类需要实现 HighAvailabilityServicesFactory 接口
具体的高可用实例对象创建则在 HighAvailabilityServicesUtils 类中有体现,如下图所示:
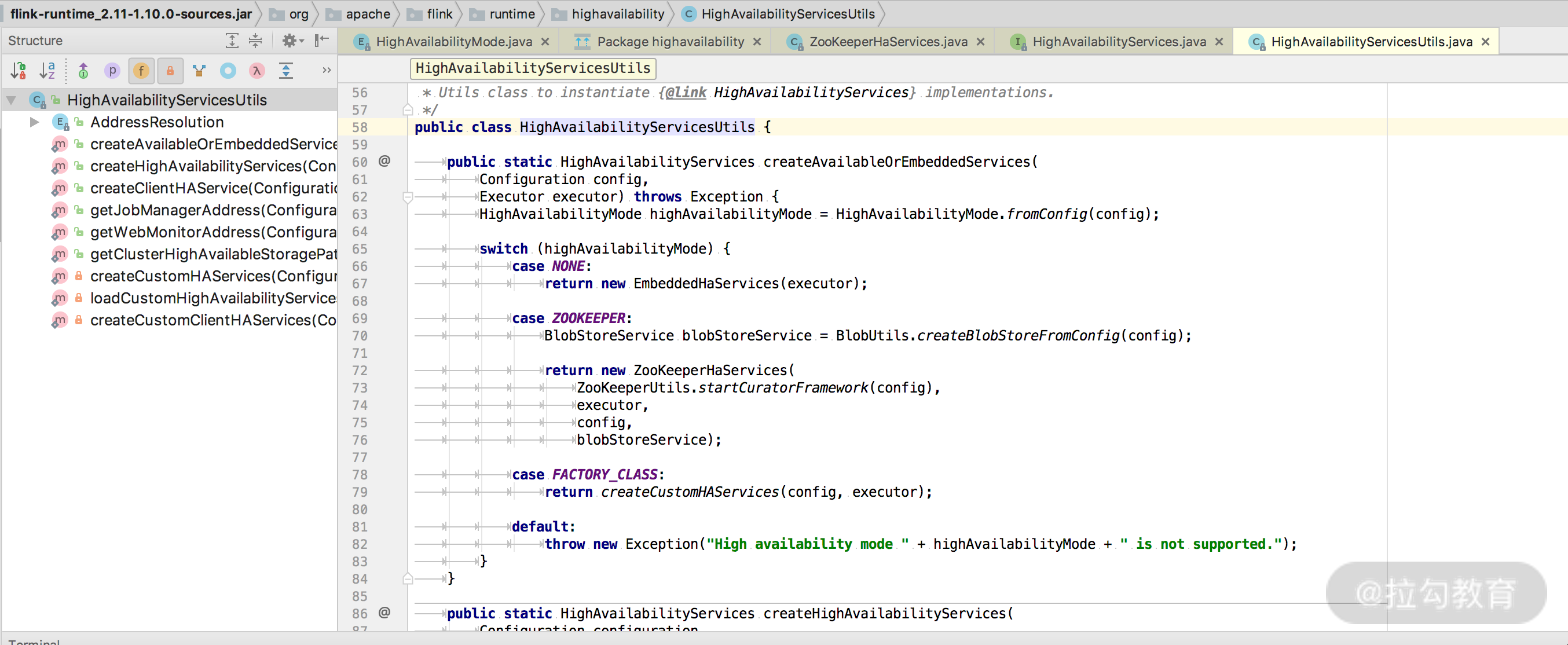
创建 HighAvailabilityServices 的实例方法如下:
public static HighAvailabilityServices createHighAvailabilityServices(
Configuration configuration,
Executor executor,
AddressResolution addressResolution) throws Exception {
HighAvailabilityMode highAvailabilityMode = LeaderRetrievalUtils.getRecoveryMode(configuration);
switch (highAvailabilityMode) {
case NONE:
// 省略部分代码
// 返回非HA服务类实例
return new StandaloneHaServices(
resourceManagerRpcUrl,
dispatcherRpcUrl,
jobManagerRpcUrl,
String.format("%s%s:%s", protocol, address, port));
case ZOOKEEPER:
BlobStoreService blobStoreService = BlobUtils.createBlobStoreFromConfig(configuration);
// 返回ZK HA 服务类实例
return new ZooKeeperHaServices(
ZooKeeperUtils.startCuratorFramework(configuration),
executor,
configuration,
blobStoreService);
case FACTORY_CLASS:
// 返回自定义 HA 服务类实例
return createCustomHAServices(configuration, executor);
default:
throw new Exception("Recovery mode " + highAvailabilityMode + " is not supported.");
}
}HighAvailabilityServices 接口定义了 HA 服务类应当实现的方法,实现类主要有 StandaloneHaServices(非 HA)、ZooKeeperHaServices、YarnHighAvailabilityServices。
ZooKeeperHaServices 主要提供了创建 LeaderRetrievalService 和 LeaderElectionService 等方法,并给出了各个服务组件使用的 ZK 节点名称。
ZooKeeperLeaderElectionService 实现了 LeaderElectionService 中 leader 选举和获取 leader 的方法。
public interface LeaderElectionService {
// 启动 leader 选举服务
void start(LeaderContender contender) throws Exception;
// 停止 leader 选举服务
void stop() throws Exception;
// 获取新的 leader session ID
void confirmLeaderSessionID(UUID leaderSessionID);
// 是否拥有 leader
boolean hasLeadership(@Nonnull UUID leaderSessionId);
}Standalone 集群高可用配置
简介
如果你的集群是 Standalone 模式,那么此时需要对 JobManager 做主备,一般推荐一个主 JobManager 和多个备用的 JobManagers。当你的主 JobManager 发生故障时,备用的 JobManager 会接管集群,以保证我们的任务正常运行。这里需要注意的是,主和备 JobManager 只是我们人为的区分,实际上它们并没有区别,每一个 JobManager 都可以当作主或者备。
Standalone 模式下的 HA 配置,Flink 依赖 ZooKeeper 实现。ZooKeeper 集群独立于 Flink 集群之外,主要被用来进行 Leader 选举和轻量级状态一致性存储。更多关于 ZooKeeper 的资料可以直接点击这里查看。
文件配置
在这里我们要特别说明的是,Flink 自带了一个简单的 ZooKeeper 集群,并且提供了一键启动的脚本。在实际生产环境中建议自己搭建 ZooKeeper 集群,以方便我们进行配置管理。
假设我们在 3 台虚拟机之间搭建 standalone 集群,并且进行高可用配置:
IP hostname 备注
192.168.2.100 master 主节点、ZK 01
192.168.2.101 slave01 从节点 01、ZK 02
192.168.2.102 slave02 从节点 02、ZK 03我们需要在 3 台机器上同时修改 Flink 配置文件中的 master 文件:
master:8081
slave01:8081
slave02:8081
表示指定 ZooKeeper 集群的访问地址。
然后,需要修改 conf/flink-conf.yaml 文件,与高可用的配置相关的几个参数,如下所示
#========================================================
# High Availability
#=====================================================================
high-availability: zookeeper
high-availability.zookeeper.quorum: localhost:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_one
high-availability.storageDir: hdfs:///flink/recovery
它们分别代表:- high-availability,高可用性模式设置为 zookeeper,用来打开高可用模式;
- high-availability.zookeeper.quorum,指定一组 ZooKeeper 服务器,它提供分布式协调服务,Flink 可以在指定的地址和端口访问 ZooKeeper;
- high-availability.zookeeper.path.root,指定 ZooKeeper 的根节点,并且在该节点下放置所有集群节点;
- high-availability.cluster-id,为每个集群指定一个 ID,用来存储该集群的相关数据;
- high-availability.storageDir,高可用存储目录,JobManager 的元数据保存在文件系统 storageDir 中,一般来讲是 HDFS 的地址。
对于 flink-conf.yaml 文件中的配置,除了 jobmanager.rpc.address 和 jobmanager.web.address 都各自配置自己机器的 IP 之外,其他的关于高可用的配置一模一样。
这里特别要注意下对于高可用性配置的部分。其中,high-availability、high-availability.storageDir 和 high-availability.zookeeper.quorum 这三项是必须配置的;后两项 high-availability.zookeeper.path.root 和 high-availability.cluster-id 配置是可选的,但是通常我们建议都手动进行配置,方便排查问题。
Yarn 集群高可用配置
与 Standalone 集群不同的是,Flink on Yarn 的高可用配置只需要一个 JobManager。当 JobManager 发生失败时,Yarn 负责将其重新启动。
我们需要修改 yarn-site.yaml 文件中的配置,如下所示:
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>yarn.resourcemanager.am.max-attempts 表示 Yarn 的 application master 的最大重试次数。
除了上述 HA 配置之外,还需要配置 flink-conf.yaml 中的最大重试次数:
yarn.application-attempts: 10 默认情况下,该配置的值为 2:
我们在 Flink 的官网中可以查到,当你的 yarn.application-attempts 配置为 10 的时候:
这意味着如果程序启动失败,YARN 会再重试 9 次(9 次重试 + 1 次启动),如果 YARN 启动 10 次作业还失败,则 YARN 才会将该任务的状态置为失败。如果发生进程抢占,节点硬件故障或重启,NodeManager 重新同步等,YARN 会继续尝试启动应用。 这些重启不计入 yarn.application-attempts 个数中。
同时官网给出了重要提示:
YARN 2.3.0 < version < 2.4.0. All containers are restarted if the application master fails.
YARN 2.4.0 < version < 2.6.0. TaskManager containers are kept alive across application master failures. This has the advantage that the startup time is faster and that the user does not have to wait for obtaining the container resources again.
YARN 2.6.0 <= version: Sets the attempt failure validity interval to the Flinks’ Akka timeout value. The attempt failure validity interval says that an application is only killed after the system has seen the maximum number of application attempts during one interval. This avoids that a long lasting job will deplete it’s application attempts.不同 Yarn 版本的容器关闭行为不同,需要我们特别注意。
YARN 2.3.0 < YARN 版本 < 2.4.0。如果 application master 进程失败,则所有的 container 都会重启。
YARN 2.4.0 < YARN 版本 < 2.6.0。TaskManager container 在 application master 故障期间,会继续工作。这样的优点是:启动时间更快,且缩短了所有 task manager 启动时申请资源的时间。
YARN 2.6.0 <= YARN 版本:失败重试的间隔会被设置为 Akka 的超时时间。在一次时间间隔内达到最大失败重试次数才会被置为失败。
另外,需要注意的是,假如你的 ZooKeeper 集群使用 Kerberos 安全模式运行,那么可以根据需要添加下面的配置:
zookeeper.sasl.service-name
zookeeper.sasl.login-context-name
如果你不想搭建自己的 ZooKeeper 集群或者简单地进行本地测试,你可以使用 Flink 自带的 ZooKeeper 集群,但是并不推荐,我们建议读者搭建自己的 ZooKeeper 集群。
总结
本课时我们主要讲解了 Flink 集群的高可用配置,Standalone 和 Yarn 集群的配置有所不同。在生产环境中,Flink 集群的高可用配置必不可少,并且我们从源码上简单分析了高可用配置的原理。




文章评论