
Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
- 第10讲:Flink Side OutPut 分流
- 第11讲:Flink CEP 复杂事件处理
- 第12讲:Flink 常用的 Source 和 Connector
- 第13讲:如何实现生产环境中的 Flink 高可用配置
- 第14讲:Flink Exactly-once 实现原理解析
- 第15讲:如何排查生产环境中的反压问题
- 第16讲:如何处理Flink生产环境中的数据倾斜问题
- 第17讲:生产环境中的并行度和资源设置
这一课时我们主要讲解 Flink 的状态和容错。
在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。
状态
我们在 Flink 的官方博客中找到这样一段话,可以认为这是对状态的定义:
When working with state, it might also be useful to read about Flink’s state backends. Flink provides different state backends that specify how and where state is stored. State can be located on Java’s heap or off-heap. Depending on your state backend, Flink can also manage the state for the application, meaning Flink deals with the memory management (possibly spilling to disk if necessary) to allow applications to hold very large state. State backends can be configured without changing your application logic.
这段话告诉我们,所谓的状态指的是,在流处理过程中那些需要记住的数据,而这些数据既可以包括业务数据,也可以包括元数据。Flink 本身提供了不同的状态管理器来管理状态,并且这个状态可以非常大。
Flink 的状态数据可以存在 JVM 的堆内存或者堆外内存中,当然也可以借助第三方存储,例如 Flink 已经实现的对 RocksDB 支持。Flink 的官网同样给出了适用于状态计算的几种情况:
- When an application searches for certain event patterns, the state will store the sequence of events encountered so far
- When aggregating events per minute/hour/day, the state holds the pending aggregates
- When training a machine learning model over a stream of data points, the state holds the current version of the model parameters
- When historic data needs to be managed, the state allows efficient access to events that occurred in the past
以上四种情况分别是:复杂事件处理获取符合某一特定时间规则的事件、聚合计算、机器学习的模型训练、使用历史的数据进行计算。
Flink 状态分类和使用
我们在之前的课时中提到过 KeyedStream 的概念,并且介绍过 KeyBy 这个算子的使用。在 Flink 中,根据数据集是否按照某一个 Key 进行分区,将状态分为 Keyed State 和 Operator State(Non-Keyed State)两种类型。
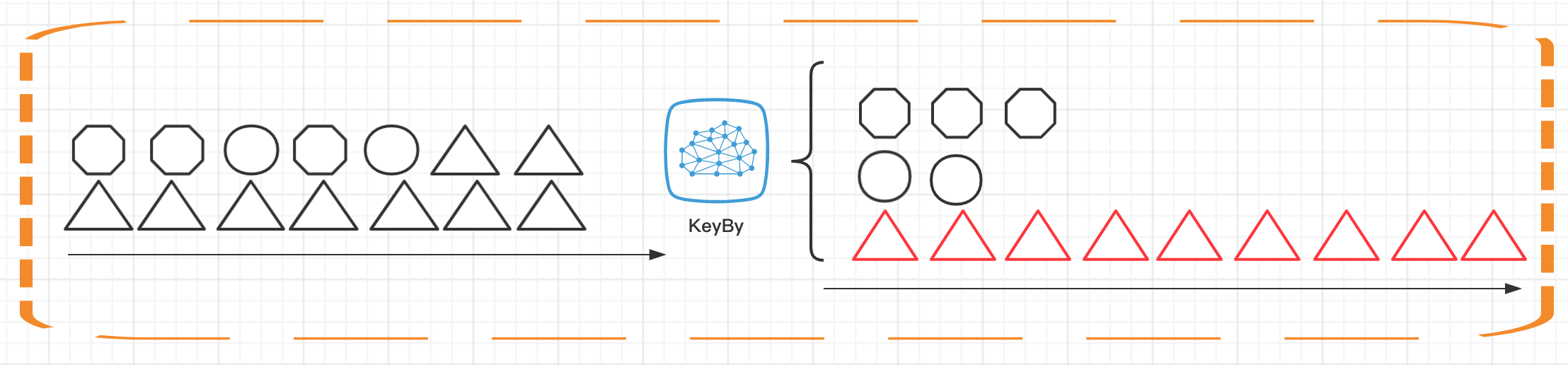
如上图所示,Keyed State 是经过分区后的流上状态,每个 Key 都有自己的状态,图中的八边形、圆形和三角形分别管理各自的状态,并且只有指定的 key 才能访问和更新自己对应的状态。
与 Keyed State 不同的是,Operator State 可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。每个算子子任务上的数据共享自己的状态。
但是有一点需要说明的是,无论是 Keyed State 还是 Operator State,Flink 的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
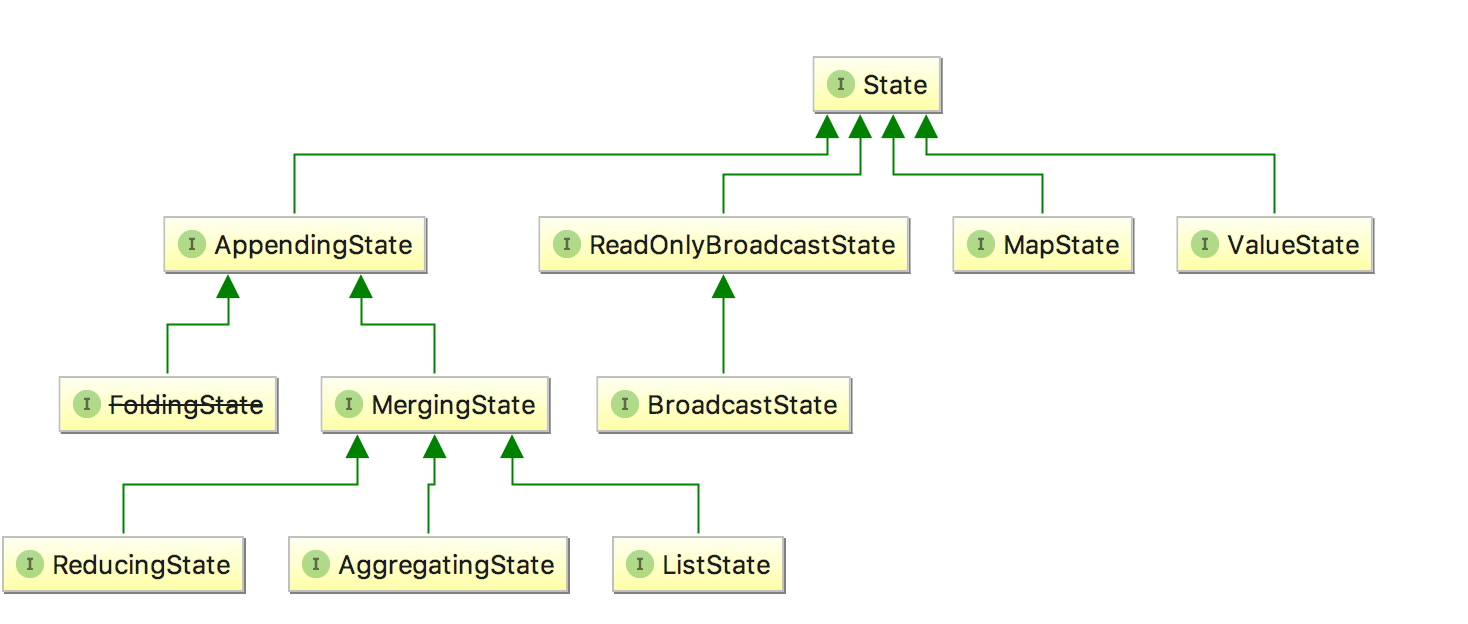
我们可以看一下 State 的类图,对于 Keyed State,Flink 提供了几种现成的数据结构供我们使用,State 主要有四种实现,分别为 ValueState、MapState、AppendingState 和 ReadOnlyBrodcastState ,其中 AppendingState 又可以细分为ReducingState、AggregatingState 和 ListState。
那么我们怎么访问这些状态呢?Flink 提供了 StateDesciptor 方法专门用来访问不同的 state,类图如下:
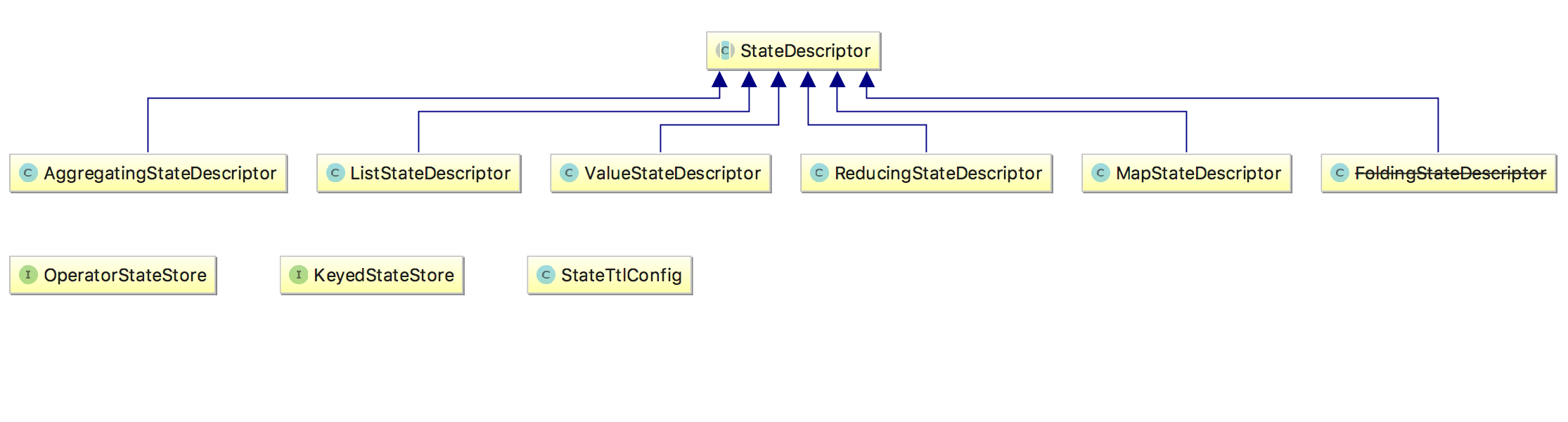
下面演示一下如何使用 StateDesciptor 和 ValueState,代码如下:
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 5L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new CountWindowAverage())
.printToErr();
env.execute("submit job");
}
public static class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
private transient ValueState<Tuple2<Long, Long>> sum;
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
Tuple2<Long, Long> currentSum;
// 访问ValueState
if(sum.value()==null){
currentSum = Tuple2.of(0L, 0L);
}else {
currentSum = sum.value();
}
// 更新
currentSum.f0 += 1;
// 第二个元素加1
currentSum.f1 += input.f1;
// 更新state
sum.update(currentSum);
// 如果count的值大于等于2,求知道并清空state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // state的名字
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {})
); // 设置默认值
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
descriptor.enableTimeToLive(ttlConfig);
sum = getRuntimeContext().getState(descriptor);
}
}在上述例子中,我们通过继承 RichFlatMapFunction 来访问 State,通过 getRuntimeContext().getState(descriptor) 来获取状态的句柄。而真正的访问和更新状态则在 Map 函数中实现。
我们这里的输出条件为,每当第一个元素的和达到二,就把第二个元素的和与第一个元素的和相除,最后输出。我们直接运行,在控制台可以看到结果:
Operator State 的实际应用场景不如 Keyed State 多,一般来说它会被用在 Source 或 Sink 等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证 Flink 应用的 Exactly-Once 语义。
同样,我们对于任何状态数据还可以设置它们的过期时间。如果一个状态设置了 TTL,并且已经过期,那么我们之前保存的值就会被清理。
想要使用 TTL,我们需要首先构建一个 StateTtlConfig 配置对象;然后,可以通过传递配置在任何状态描述符中启用 TTL 功能。
复制代码
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
descriptor.enableTimeToLive(ttlConfig);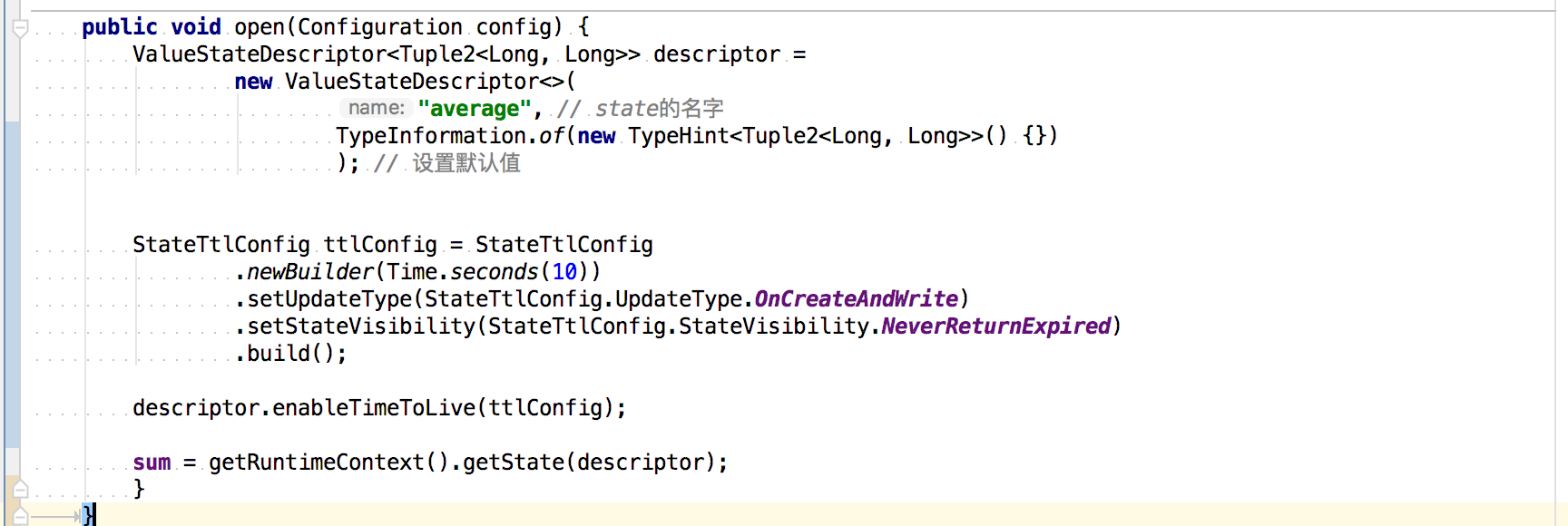
StateTtlConfig 这个类中有一些配置需要我们注意:
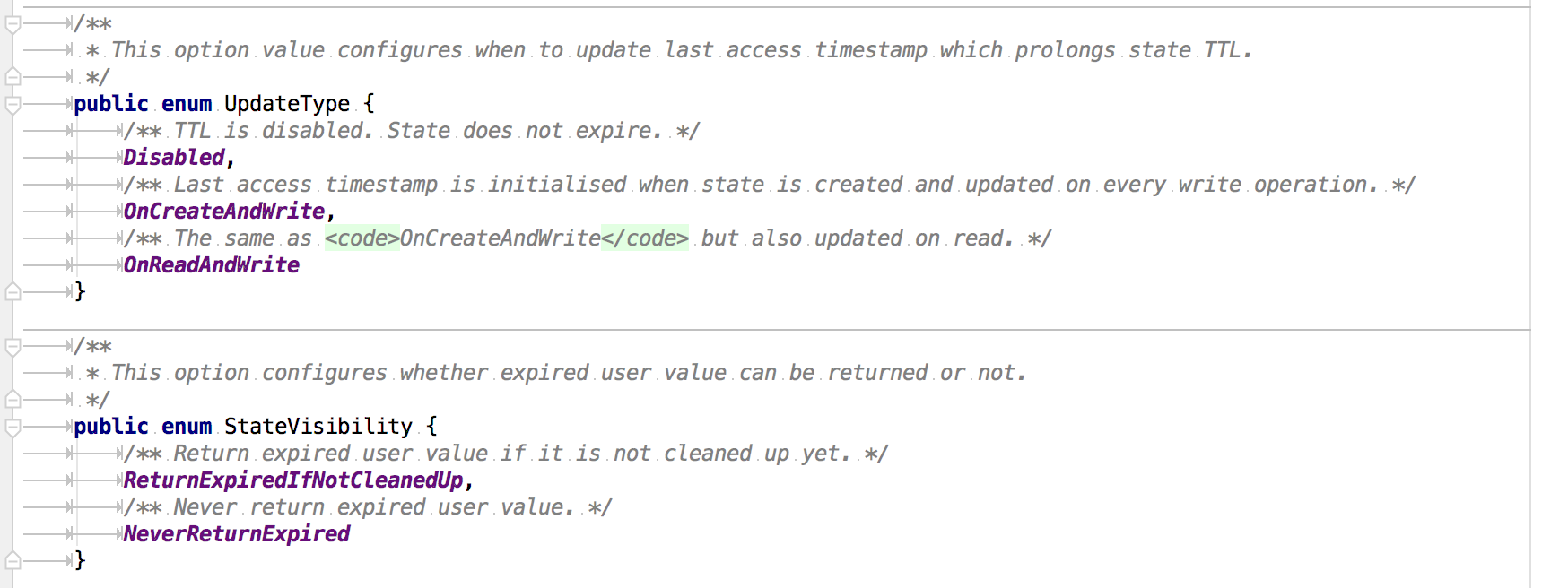
UpdateType 表明了过期时间什么时候更新,而对于那些过期的状态,是否还能被访问则取决于 StateVisibility 的配置。
状态后端种类和配置
我们在上面的内容中讲到了 Flink 的状态数据可以存在 JVM 的堆内存或者堆外内存中,当然也可以借助第三方存储。默认情况下,Flink 的状态会保存在 taskmanager 的内存中,Flink 提供了三种可用的状态后端用于在不同情况下进行状态后端的保存。
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
MemoryStateBackend
顾名思义,MemoryStateBackend 将 state 数据存储在内存中,一般用来进行本地调试用,我们在使用 MemoryStateBackend 时需要注意的一些点包括:
每个独立的状态(state)默认限制大小为 5MB,可以通过构造函数增加容量
状态的大小不能超过 akka 的 Framesize 大小
聚合后的状态必须能够放进 JobManager 的内存中
MemoryStateBackend 可以通过在代码中显示指定:
复制代码
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false));其中,new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false) 中的 false 代表关闭异步快照机制。关于快照,我们在后面的课时中有单独介绍。
很明显 MemoryStateBackend 适用于我们本地调试使用,来记录一些状态很小的 Job 状态信息。
FsStateBackend
FsStateBackend 会把状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中,少量的元数据信息存储到 JobManager 的内存中。
使用 FsStateBackend 需要我们指定一个文件路径,一般来说是 HDFS 的路径,例如,hdfs://namenode:40010/flink/checkpoints。
我们同样可以在代码中显示指定:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints", false));FsStateBackend 因为将状态存储在了外部系统如 HDFS 中,所以它适用于大作业、状态较大、全局高可用的那些任务。
RocksDBStateBackend
RocksDBStateBackend 和 FsStateBackend 有一些类似,首先它们都需要一个外部文件存储路径,比如 HDFS 的 hdfs://namenode:40010/flink/checkpoints,此外也适用于大作业、状态较大、全局高可用的那些任务。
但是与 FsStateBackend 不同的是,RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 运行节点的数据目录下。
这意味着,RocksDBStateBackend 可以存储远超过 FsStateBackend 的状态,可以避免向 FsStateBackend 那样一旦出现状态暴增会导致 OOM,但是因为将状态数据保存在 RocksDB 数据库中,吞吐量会有所下降。
此外,需要注意的是,RocksDBStateBackend 是唯一支持增量快照的状态后端。
总结
我们在这一课时中讲解了 Flink 中的状态分类和使用,并且用实际案例演示了用法;此外介绍了 Flink 状态的保存方式和优缺点。




文章评论