
Hive系列文章
- Hive表的基本操作
- Hive中的集合数据类型
- Hive动态分区详解
- hive中orc格式表的数据导入
- Java通过jdbc连接hive
- 通过HiveServer2访问Hive
- SpringBoot连接Hive实现自助取数
- hive关联hbase表
- Hive udf 使用方法
- Hive基于UDF进行文本分词
- Hive窗口函数row number的用法
- 数据仓库之拉链表
Hbase是一种NoSQL数据库,这意味着它不像传统的RDBMS数据库那样支持SQL作为查询语言。一种方法是使用hive关联hbase表,可以完成对hbase表的数据插入(insert)和查询(select)。
Hive和HBase的通信原理
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,这种相互通信是通过$HIVE_HOME/lib/hive-hbase-handler-{hive.version}.jar工具类实现的。通过HBaseStorageHandler,Hive可以获取到Hive表所对应的HBase表名,列簇和列,InputFormat、OutputFormat类,创建和删除HBase表等。Hive访问HBase中表数据,实质上是通过MapReduce读取HBase表数据,其实现是在MR中,使用HiveHBaseTableInputFormat完成对HBase表的切分,获取RecordReader对象来读取数据。对HBase表的切分原则是一个Region切分成一个Split,即表中有多少个Regions,MR中就有多少个Map;读取HBase表数据都是通过构建Scanner,对表进行全表扫描,如果有过滤条件,则转化为Filter。当过滤条件为rowkey时,则转化为对rowkey的过滤;Scanner通过RPC调用RegionServer的next()来获取数据;
基本通信原理如下:
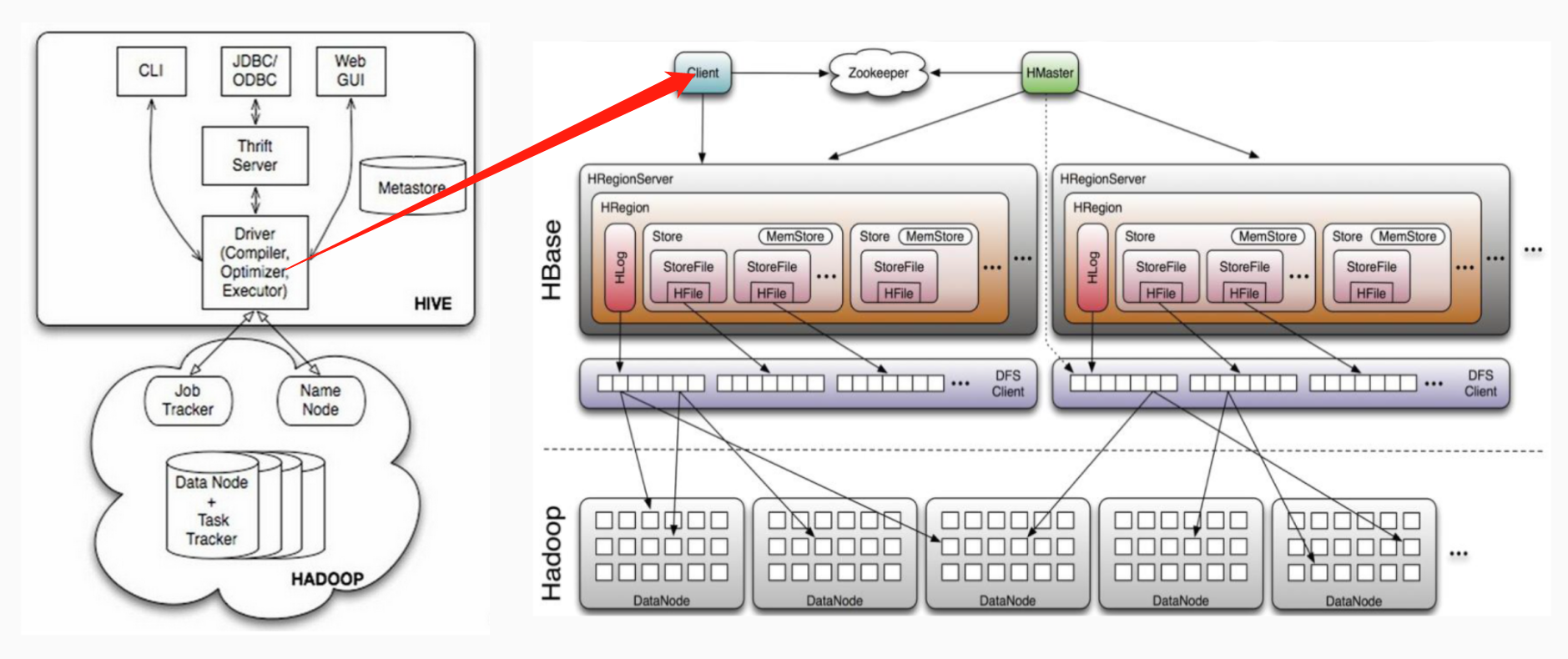
新建hive表关联hbase表
hive关联的hbase表,对应的hbase表如果不存在,会自动创建,test是hbase的一个namespace,相当于mysql中的database需要提前建好:create_namespace 'test'。
create table if not exists test.test
(
id string comment '用户id',
name string comment '姓名'
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping" = ":key,info:name")
tblproperties("hbase.table.name" = "test:test");上面的命令创建了一张hive表,跟hbase表是联系在一起的,对应关系:
| 名称 | 含义 | |
|---|---|---|
| id | :key,即对应hbase表的rowkey | |
| name | 对应hbase的info列簇name字段 | |
| hive表名:test.test | hbase表名:test:test |
表名可以不相同的,但是通常为了统一,表命建得相同。
通过hive插入数据到hbase表
如果有这么一个需求,我们想把hive一张结果表存一份数据到hbase,可以使用insert select方式,将hive表的数据插入到hbase表中去。假设现在有一张hive表test.test2:
hive> select * from test.test2;
OK
1 tom
2 jack
3 alice将hive表test.test2的数据导入到hbase表:
insert into test.test select * from test.test2;这就将数据导入hbase表了,这时候不管是在hive里面,还是hbase shell里面,都是可以直接查询到数据的。
hive> select * from test.test;
OK
1 tom
2 jack
3 alice从hbase里面scan也是有数据的。
hbase(main):005:0> scan 'test:test'
ROW COLUMN+CELL
1 column=info:name, timestamp=1590221288866, value=tom
2 column=info:name, timestamp=1590221288866, value=jack
3 column=info:name, timestamp=1590221288866, value=alice 实际数据是存储在hbase数据目录里面的:
[hadoop@slave3 ~]$ hdfs dfs -ls /hbase/data/test/test
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2020-05-23 16:05 /hbase/data/test/test/.tabledesc
drwxr-xr-x - hadoop supergroup 0 2020-05-23 16:05 /hbase/data/test/test/.tmp
drwxr-xr-x - hadoop supergroup 0 2020-05-23 16:05 /hbase/data/test/test/722a0bfced3a534029e5093ebba1d55c
[hadoop@slave3 ~]$ hdfs dfs -ls /user/hive/warehouse/test.db/test对hbase表做统计查询
有时候我们想对hbase表的数据进行统计分析,可以通过mapreduce / spark API,通过代码逻辑统计分析,但是这些成本有点高,能用sql的尽量用sql做大数据分析,这时候hive关联hbase表查询就派上用场了。
hive> select name, count(1) from test.test group by name;
alice 1
jack 1
tom 1



文章评论